Zurück zur Startseite
OpenSanctions
Wir zeigen, welche Firmen und Personen von internationalen Sanktionen betroffen sind.
OpenSanctions ist eine Ressource für Journalist\*innen, Aktivist\*innen und Finanzdienstleister. Das Projekt sammelt Profile über Personen und Firmen, denen ein besonderes öffentliches Interesse gilt.

Was ist OpenSanctions?
OpenSanctions ist eine Ressource für Journalist*innen, Aktivist*innen und Finanzdienstleister. Das Projekt sammelt Profile über Personen und Firmen, die Ziel internationaler Sanktionen sind. Hinzu kommen Einträge zu Personen, die aufgrund von kriminellem Verhalten oder als politische Mandatsträger*innen (sog. PEPs) ins öffentliche Interesse gerückt sind.
Solche Profile sind ein wichtiges Werkzeug, um in großen Datenmengen systematisch Hinweise auf Interessenkonflikte, Korruption und Geldwäsche zu finden. Zudem stellen Sanktionen eine Art quantifizierte Geopolitik dar: Sie dokumentieren in ungewöhnlicher Klarheit, welche außenpolitischen Ziele unterschiedliche Staaten verfolgen.
Weil die Daten jedoch nicht leicht auffindbar sind, ist ihre Nutzung bisher technisch aufwändig. Konsolidierte Datenbanken, die von Firmen wie Dow Jones oder Refinitiv angeboten werden, sind für Journalist*innen und Aktivist*innen unerschwinglich. OpenSanctions macht diese Quellen für sie deshalb einfach, gratis und strukturiert nutzbar.
Gerd, wie baut man eine Pipeline?
Sanktionsdaten werden in der Regel von Regierungsbeamt*innen in veraltete Computersysteme getippt, die diese dann auf einer Website bereitstellen (oft als XML oder JSON, manchmal aber auch als PDF oder Excel-Datei). Dabei entstehen natürlich (sowohl durch die Beamt*innen wie auch durch die Systeme) verschiedene Probleme: Wie buchstabiert man etwa einen arabischen Namen im lateinischen Alphabet? Oder einen russischen Namen auf Hebräisch? Welche Länder gibt es? In welchem Land befindet sich ein*e Einwohner*in der Stadt Sevastopol? Wie formatiert man eine Telefonnummer oder Hausadresse? Mit welcher Identifikationsnummer beschreibt man eine Firma oder Person am besten?
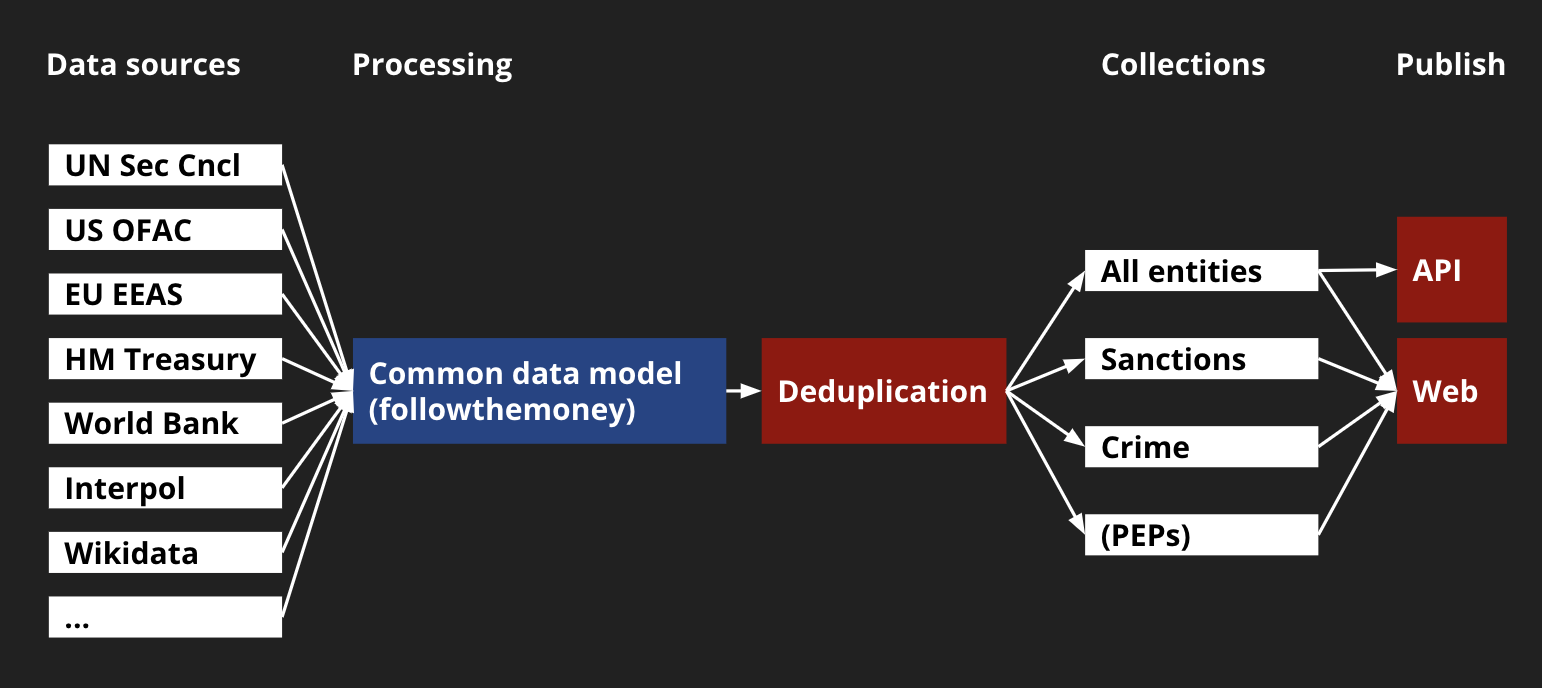
Ein wesentlicher Teil der Arbeit an OpenSanctions besteht darin, die unterschiedlichen Quellformate in eine neue, kohärente Datenstruktur zu überführen. Der Ansatz ist, alle Bereinigungen vollständig reproduzierbar und transparent zu machen. Um die Verarbeitung transparent zu machen, wird der ganze Prozess öffentlich einsehbar bei GitHub Actions ausgeführt, und alle entstehenden Fehlermeldungen oder Warnungen werden auf der OpenSanctions-Webseite in der Beschreibung des Datensatzes veröffentlicht.
Eine hilfreiche Komponente für die Reproduzierbarkeit waren Normalisierungstabellen, die Ländercodes, Adressen oder Zeitangaben vereinheitlichen. Für deren systematische Anwendung habe ich die Python-Bibliothek datapatch veröffentlicht.
Neben der strukturellen Angleichung der Daten gab es noch ein zweites, komplexes Problem zu lösen: Die verschiedenen Datenquellen - vor allem die Sanktionslisten verschiedener Staaten - enthalten immer wieder die gleichen Personen und Organisationen. Zum ehemaligen irakischen Präsidenten Saddam Hussein, zum Beispiel, kennt das System Einträge aus 13 Quellen. Stattdessen sollte eine konsolidierte Ansicht angeboten werden. Dazu habe ich die Python-Bibliothek nomenklatura weiterentwickelt, die mögliche Duplikate erkennt und auch verschmelzen kann.
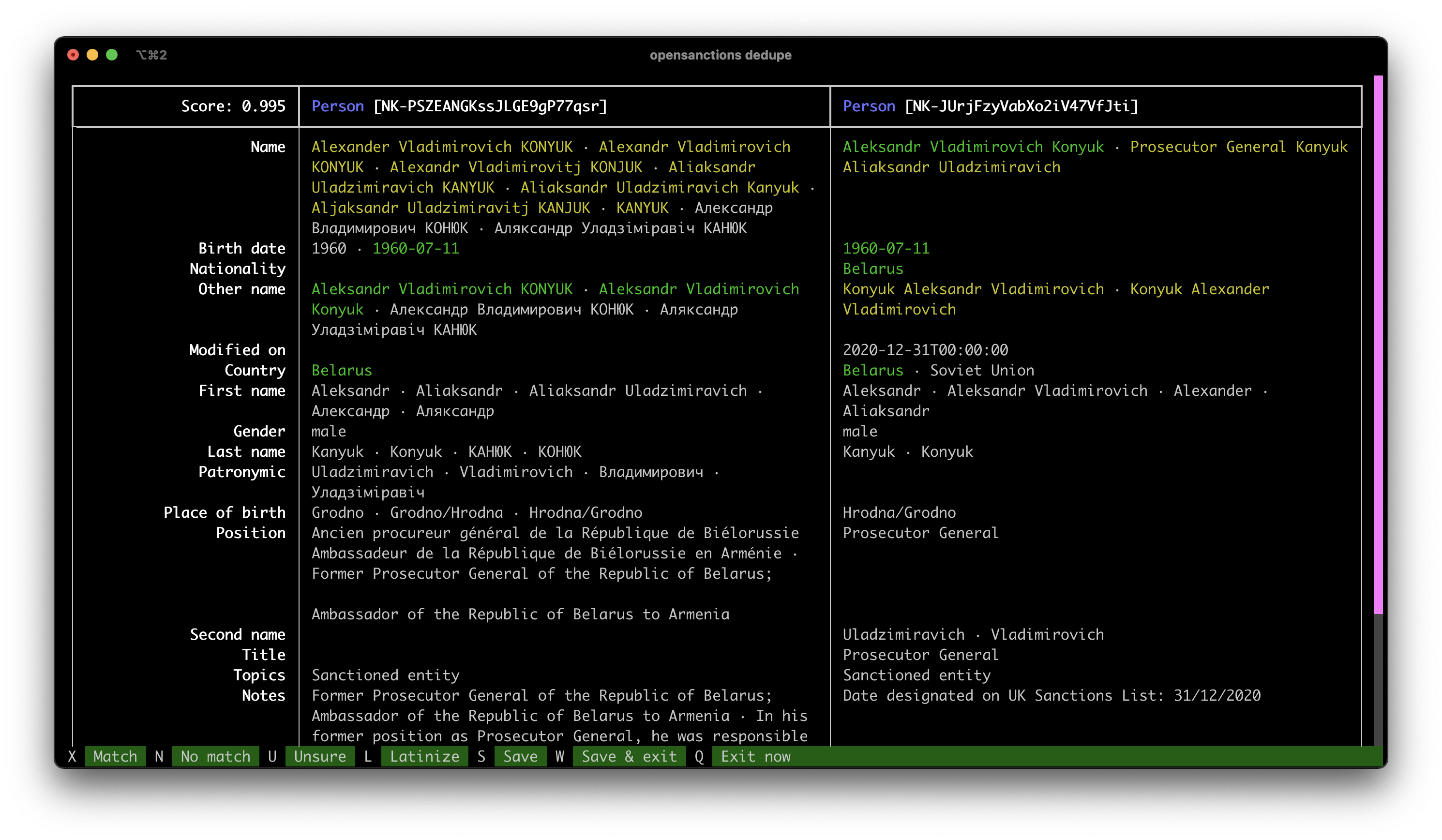
Um eine hohe Qualität des Datensatzes sicherzustellen, wurde ein manueller Prüfungsschritt eingeführt, mit dem die Richtigkeit des Matches durch einen Menschen bestätigt wird. Zur Duplikationsstrategie gibt es auch einen detaillierten Blogpost.
Die Daten nutzbar machen
Schon zum Projektstart ging eine einfache Webseite online, auf der Anwender*innen die produzierten Datensätze in verschiedenen Formaten herunterladen konnten. Im Verlauf des Projekts kam dann noch eine umfangreiche Dokumentation der verwendeten Datenstruktur und der Methodik hinzu. Aktuelle Entwicklungen wurden in einem Blog dokumentiert.
Bedauernswerterweise ist das Feedback der Nutzer*innen zu den bereitgestellten Dateiformaten bisher spärlich gewesen: Zwar wurden einige spezifische Erweiterungen vorgeschlagen, aber ich hatte zu dem Thema auf mehr Dialog gehofft.
Entgegen der ursprünglichen Pläne habe ich mich schließlich dazu entschlossen, die Daten auch inhaltlich auf der Webseite zugänglich zu machen. Um eine Suchfunktion und die Darstellung einzelner Einträge zu ermöglichen, habe ich einen alleinstehenden API-Server entwickelt, der die OpenSanctions-Daten in ElasticSearch durchsuchbar macht.
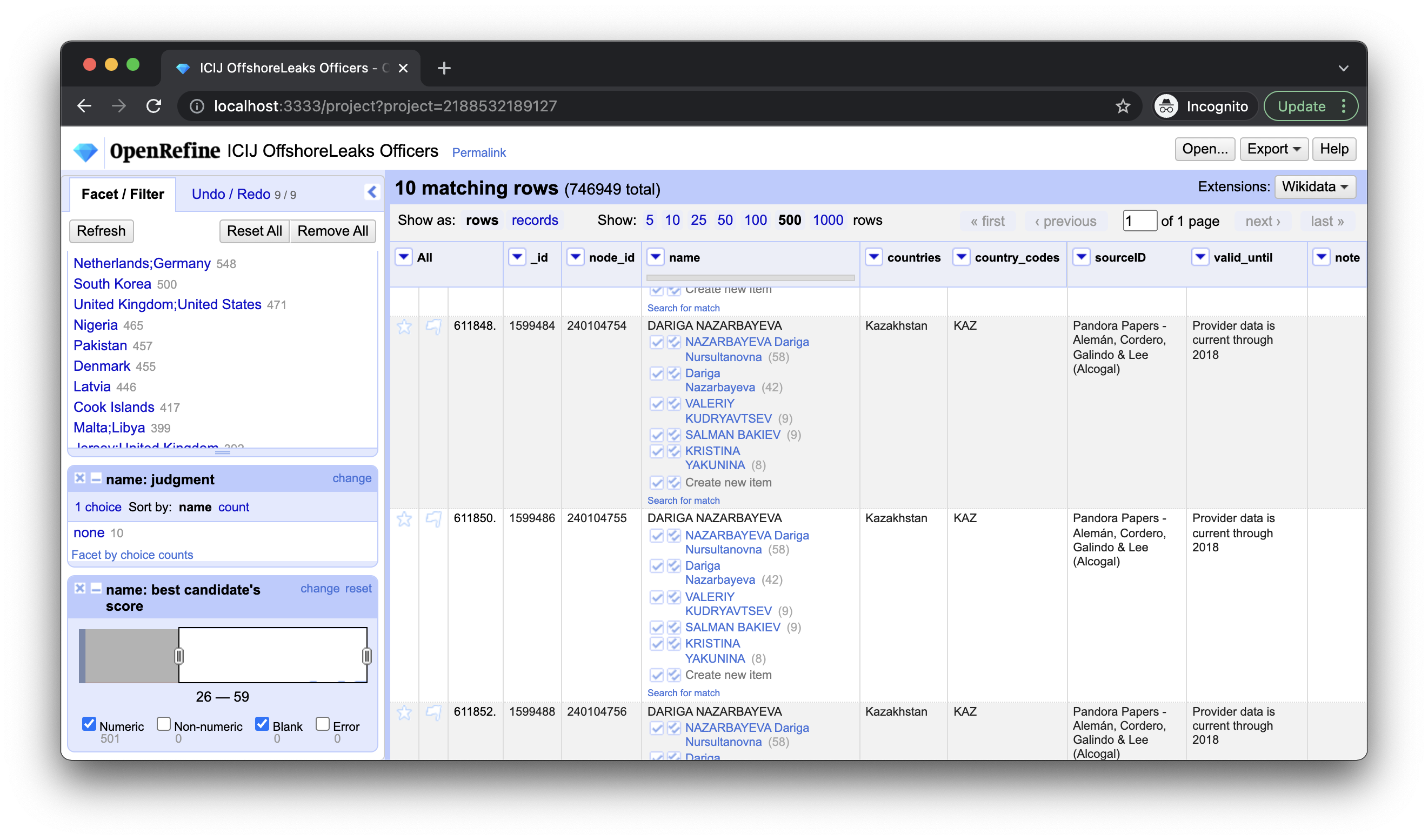
Mithilfe einer Implementation der OpenRefine Reconciliation API kann dieser etwa Journalist*innen auch dabei helfen, einen ganze Liste von Firmen oder Personen auf relevante Einträge zu überprüfen.
Dazu kommt eine Matching-API, mit der etwa Firmen ihren eigenen Kundenstamm mit der Datenbank abgleichen können. Damit solche Kundendaten nicht in die Projekt-Infrastruktur wandern müssen, ist der API-Server als Docker-Image abgepackt. Das kann einfach auf dem Server der Anwender*innen installiert werden und holt sich jede Stunde aktuelle Daten von OpenSanctions ab.
Weil die Qualität des Matchers für die kommerzielle Nutzung von OpenSanctions von großer Bedeutung ist, will ich die erzeugten Scores in Zukunft durch ein Regressionsmodell generieren, das die manuell vorgenommenen Deduplikations-Entscheidungen als Trainingssatz nutzt. Das Modell produziert bisher gute Erkennungswerte, soll aber noch weiter geprüft werden, bevor es in den Produktiveinsatz übergehen kann.
Ein nettes Extra der Webseite ist die Rohdatenansicht mit der Anwender*innen genau nachvollziehen können, aus welcher Quelle welches Attribut eines Eintrags stammt.
Über den Projektzeitraum haben etwa 40.000 Menschen die Webseite besucht - davon etwa 10.000 im letzten Monat. Es ist also ein wachsendes Interesse zu beobachten.
Mehr Quellen!
Im Laufe des Projekts habe ich die Anzahl der verwendeten Datenquellen langsam erhöht. Neben den zunächst enthaltenen Sanktionslisten aus Amerika, Europa, Schweiz, Ukraine, Kanada, Großbritannien, Frankreich und den UN konnten wir zusätzliche Quellen aus Argentinien, Australien, Israel, Japan, Kyrgyzstan, Kazakhstan, Russland und Südafrika erschließen. Daneben haben wir einige thematisch verwandte Listen, etwa die Vergabevertrag-Verbotslisten aller internationalen Entwicklungsbanken und eine Liste von Blockchain-Konten, die im Zusammenhang mit Finanzkriminalität stehen, eingebunden.
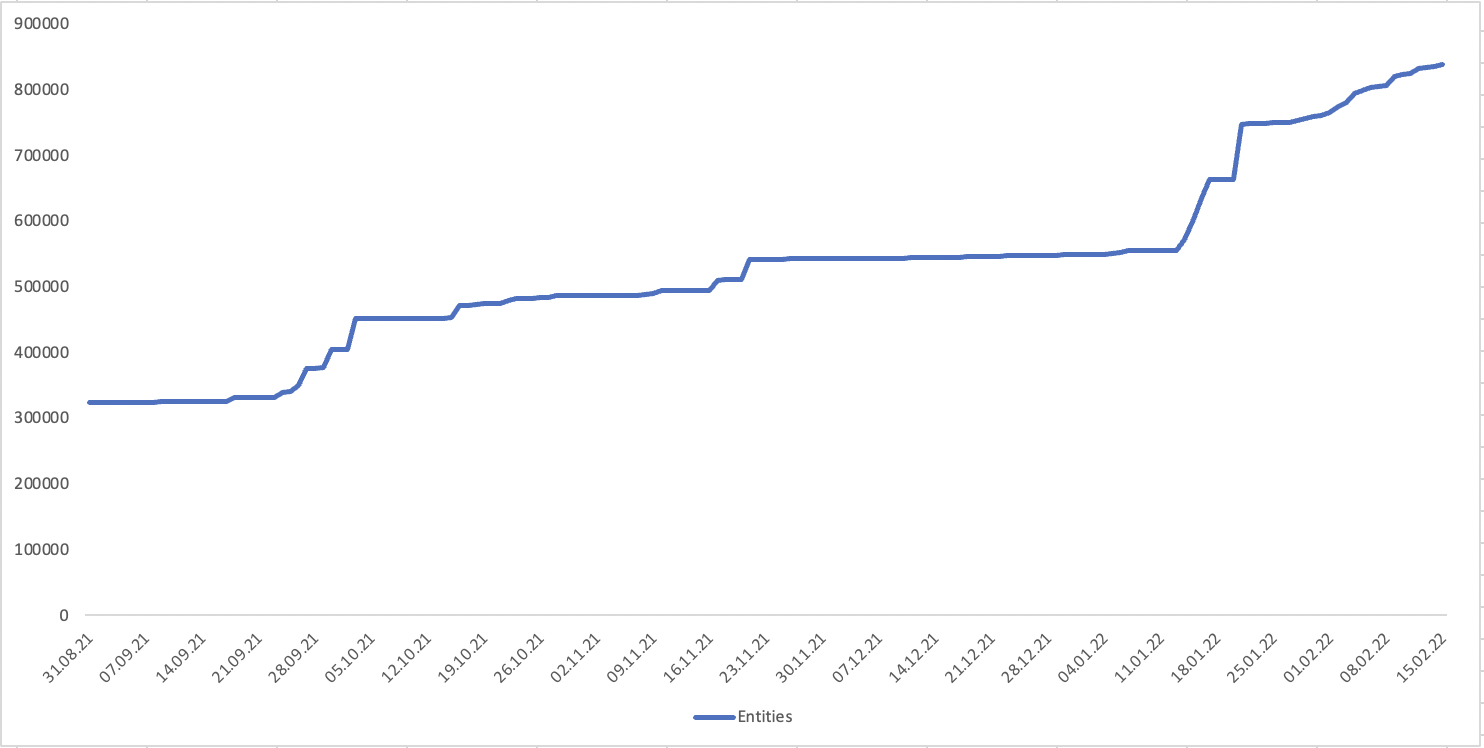
Den größten Datenzuwachs hat das Projekt allerdings nicht durch zusätzliche Sanktionslisten erfahren, sondern in einem verwandten Themenfeld: Informationen über Politiker*innen. Deren Profile sind aus ähnlichen Gründen relevant, die auch für Sanktionen gelten: Taucht ein*e Politiker*in (oder engsten Mitstreiter*innen) etwa in einem Leak auf, dann ist das häufig der Anlass für eine journalistische Recherche.
Doch ein systematisches Verzeichnis aller Politiker*innen gibt es nicht. Jede Nation der Welt hat andere Institutionen, die nicht immer Webseiten haben, und auf diesen Webseiten dann auch nicht immer preisgeben, wer denn aktuell Finanzminister*in sei.
Ich habe deshalb Kontakt mit dem Gründer des Projekts EveryPolitician.org aufgenommen, das ab 2015 Abgeordnete in aller Welt erfasste. Obwohl das Projekt mittlerweile inaktiv ist, hat er letztes Jahr angefangen, neue Scraper zu entwickeln, die zunächst alle Kabinette der Welt erschließen und in Wikidata eintragen sollen.
Weil unsere Projekte eine sehr ähnliche Zielsetzung haben, haben wir beschlossen, gemeinsam an der Integration aller in Wikidata erfassten Politiker*innen in OpenSanctions zu arbeiten. So konnten bislang beinahe 80.000 relevante Personen aus über 250 Territorien identifiziert werden.
Nachhaltigkeit
Mir war von Anfang an wichtig, zumindest die Instandhaltung des Projektes über den Förderzeitraum hinaus finanziell zu untermauern. Deshalb rief die erste Version der Webseite Firmen dazu auf, sich durch ein Sponsoring am Weiterbetrieb zu beteiligen. Nach halber Projektlaufzeit hatte das jedoch nur zu sehr begrenzter Resonanz geführt.
Deshalb habe ich im Dezember die Lizenzierung des Datensatzes von CC-BY auf CC-BY-NonCommercial geändert, mit besonderen Ausnahmeregeln für Medienunternehmen. Das führte zu einer Gruppe von Firmen, die sich bereit erklärten, zur Nutzung der Daten eine monatliche Nutzungsgebühr zu entrichten. OpenSanctions befindet sich damit auf einem plausiblen Weg zur finanziellen Nachhaltigkeit.
Wie es weitergeht
Fertig ist natürlich nichts. Neben einer schier unendlichen Liste an Datenquellen, die ich gerne einbinden würde, gibt es auch noch eine Reihe anderer Projekte, die vermutlich erst nach der Förderphase zum Zug kommen werden:
- Zum einen ist da die Anreicherung von Sanktionsdaten mit Fakten aus anderen, inhaltlich verwandten, Datenbanken. Dazu gehören neben Wikidata zum Beispiel die OffshoreLeaks-Datenbank von ICIJ, oder sogenannte Beneficial Ownership-Datenbanken in denen die Eigentümer*innen von Firmen dokumentiert sind. Die bestehende Infrastruktur zur De-Duplikation wird hier eine Rolle spielen, muss jedoch Matching-Kandidaten via Netzwerk beschaffen.
- Umgekehrt wollte ich auch gerne die Eintragung aller Sanktionsziele als Items in Wikidata in Angriff nehmen. Für die zentralen Akteur*innen gibt es natürlich bereits Einträge, aber hier eine Vollständigkeit zu erzielen, ist ein Ziel für die Zukunft.
- Schließlich bleibt auch die politische Analyse der Sanktionsdaten unerledigt. Was können uns Sanktionziele über die Außenpolitik verschiedener Staaten verraten? Etwa über die amerikanische Fokussierung auf iranische Nonproliferation, oder die europäischen Experimente in der Bestrafung des mörderischen Lukashenko-Regimes?
Fazit
Prototype Fund macht Spaß. Ich habe selten in meiner Arbeitszeit die Chance gehabt, so selbstbestimmt an einem Projekt zu arbeiten. Was ich besonders genossen habe: Das Sammeln der Sanktionsdaten an sich ist ein relativ überschaubares Problem, so dass wir im Projektzeitraum die Chance hatten, einige Teilaspekte besonders vertieft anzugehen und dennoch ein recht abgerundetes Produkt vorzulegen.
Ein großer Dank gilt dem Bundesministerium für Bildung und Forschung und dem Deutschen Zentrum für Luft- und Raumfahrt, die dieses Projekt erst ermöglicht haben. Und zuletzt natürlich an den Prototype Fund, der durch seine tolle Betreuung ein wundervolles Arbeitsumfeld geschaffen hat.